
LLMO対策の前に確認すべき「AIに届いているか」問題|原因と切り分け手順


LLMOを語る前に。あなたのサイト、そもそもAIに「届いて」いますか?
「LLMO対策やってます」という会社が、最近めちゃくちゃ増えました。
構造化データを入れた、llms.txtを置いた、E-E-A-Tを意識した記事を出した。いいことだと思う。ただ、クライアント支援に入っていて遭遇するのは、もっと手前の問題だったりします。
そもそも、そのサイトがAIに「読まれてすらいない」。
ChatGPTやClaudeにサイトを読ませようとしても、コンテンツが取れない。

AIから見ると、そのページは存在しないのと同じになっている。
入口が閉じているのに、奥の部屋の模様替えを頑張っている。
そういうことが普通に起きてます。
今日は、この「AIに届かない」問題を、何が起きて・どう調べて・どうするといいか、サクッと整理してみます。

📘 あなたの記事、AIにどう評価される? → ThinkMove Academy(無料)
実際に起きたこと(匿名で3つ)
固有名は伏せますが、どれも実際の支援先で遭遇したケースです。
ケース1:robots.txtは正しいのに、AIだけ本文を読めない
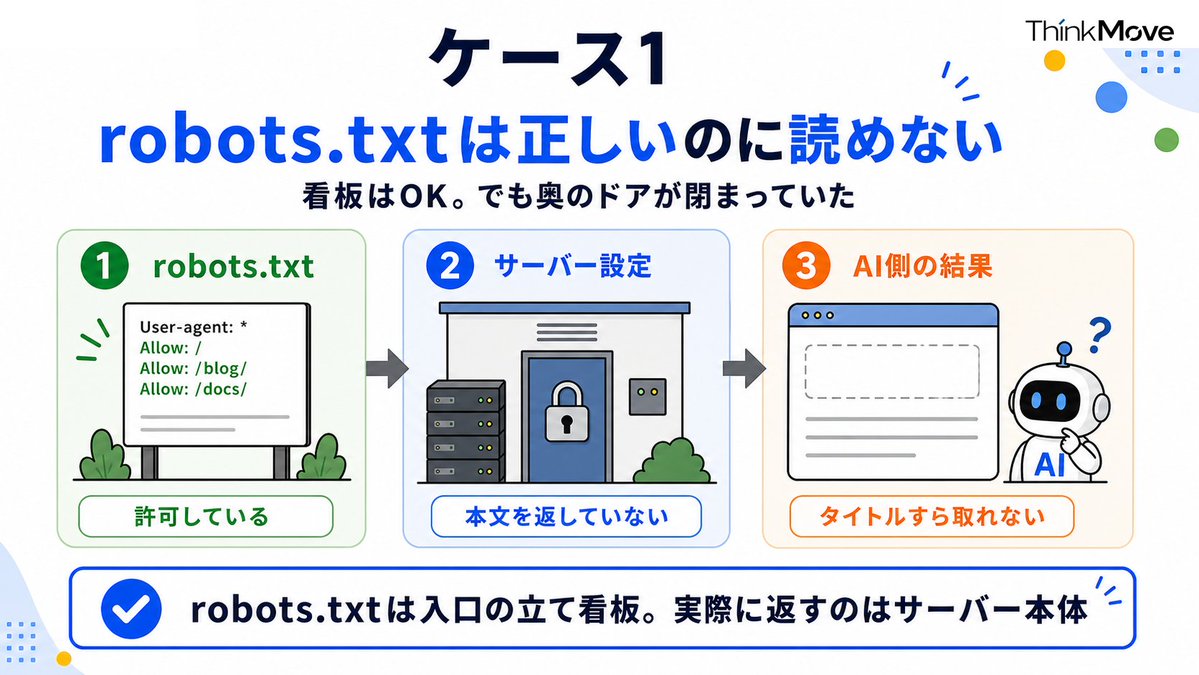
ChatGPTとClaudeの両方でブラウジングさせたら、コンテンツが取れない。タイトルすら認識されない。robots.txtを見てもおかしくない。ちゃんと許可している。
原因はrobots.txtじゃなく、サーバー側の設定でした。
robots.txtは入口の立て看板でしかなくて、実際にコンテンツを返すのはサーバー本体。看板に「どうぞ」と書いてあっても、奥のドアが閉まっていたら入れない。
ケース2:許可しているのに、応答コードがおかしくて全部弾かれる

AIクローラーを明示的に許可しているのに、なぜか全滅。調べたら、robots.txt自体が「正常です」を意味する応答(200)を返していなかった。
クローラーは「このサイトはクロールしていいのか判断できない」状態になり、安全側に倒してアクセスをやめる。許可・拒否以前に、判断材料が壊れていた。
WAFやCDN(サイトの前に置くセキュリティ・高速化の仕組み)が間に挟まっていると起きがちで、人間がブラウザで見るぶんには何ともないから、まず気づかない。
ケース3:そもそもコンテンツがJavaScriptでしか出てこない
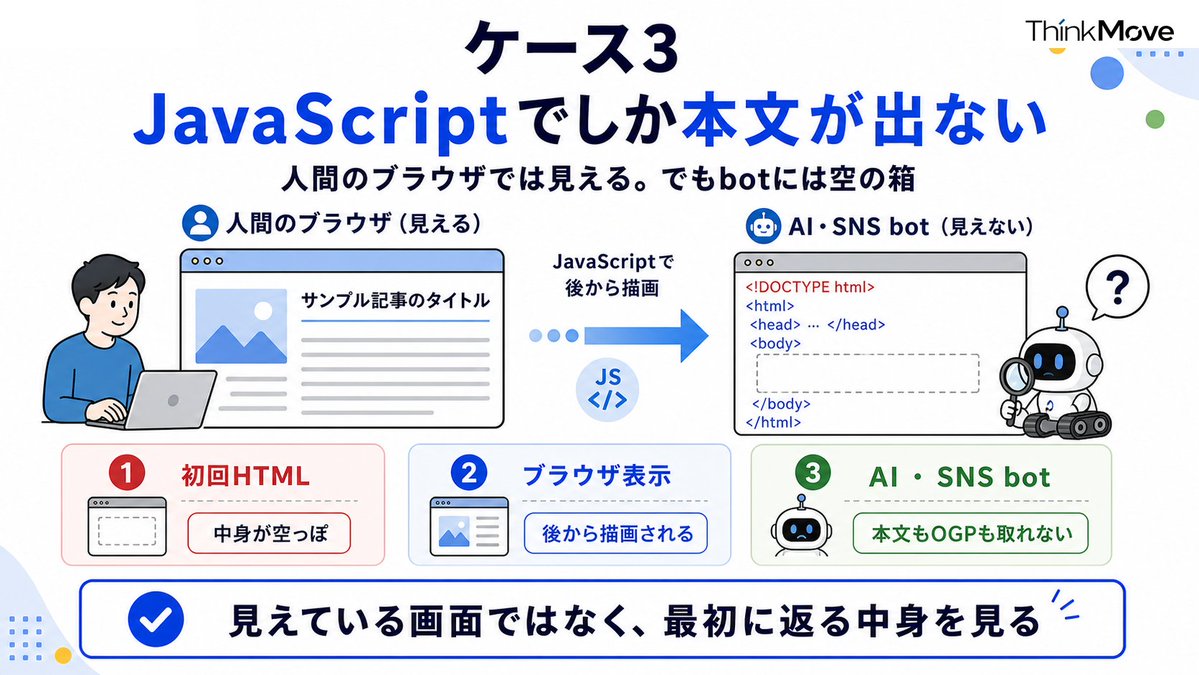
本文も見出しもタイトルも全部、表示時にプログラムで後から描画する作りで、最初に返ってくるページの中身が空っぽ。人間のブラウザはそのプログラムを動かすから普通に見えるけど、AIのクローラーやSNSのbotは中身が空の箱を受け取って帰っていく。OGP(SNSでシェアしたときに出る画像やタイトル)も出ません。
共通点は「人間には見えるから気づかない」
3つに共通するのは、運用者本人がブラウザで見ると全部ふつうに表示されることです。だから「うちは問題ない」と思い込む。人間にもGoogleにも届いている。でもAIにだけ届いていない。
AIのクローラーは、Googleよりずっと「素朴」だったりします。プログラムでの描画を待ってくれなかったり、応答が少しでも変だとすぐ諦めたり、セキュリティの仕組みに弾かれやすかったり。だから人間やGoogleでは表面化しない問題が、AIだと一気に顕在化する。
しかもこの手の問題は、サーバーのアクセスログを見ないと本当の原因が確定できないことが多いです。
だから、まず「アクセスログ」を見てほしい

不
安なときは、いきなり対策を打つ前に、サーバーのアクセスログ(誰がいつ来て、どう応答したかの記録)を見るのがおすすめです。ここで分かること。
どのAIクローラーが実際に来ているか
そのアクセスに、サーバーがちゃんと「正常(200)」で返せているか。エラーで弾いていないか
そもそもログに記録すら残っていないか
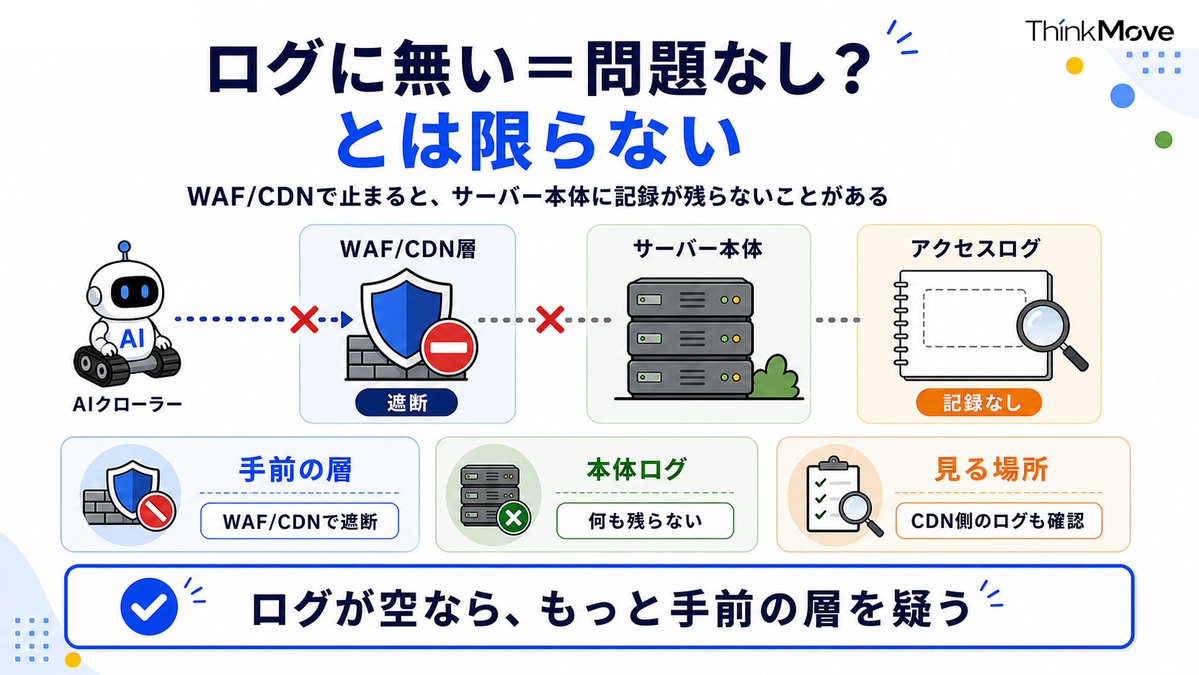
最後が地味に大事で、WAFやCDNといった「サイトの手前の層」でブロックされていると、サーバー本体のログにすら残らないことがあります。
実際、Botアクセスかました結果、エラーログ追っても何も出てこないケースはよくあります。
「ログに何も無い=問題なし」じゃなくて、「ログに無い=もっと手前で弾かれてるのかも」と読む。ここを知らないと、サーバーのログだけ見て「来てないですね」で終わってしまう。
「人間はOK・GoogleもOK・AIだけNG」という状態が、どの層で起きているか。これを順番に切り分けていくのが、遠回りなようで結局いちばん早いです。
WAFは悪者じゃない。でも“通すべきもの”まで止めてないか
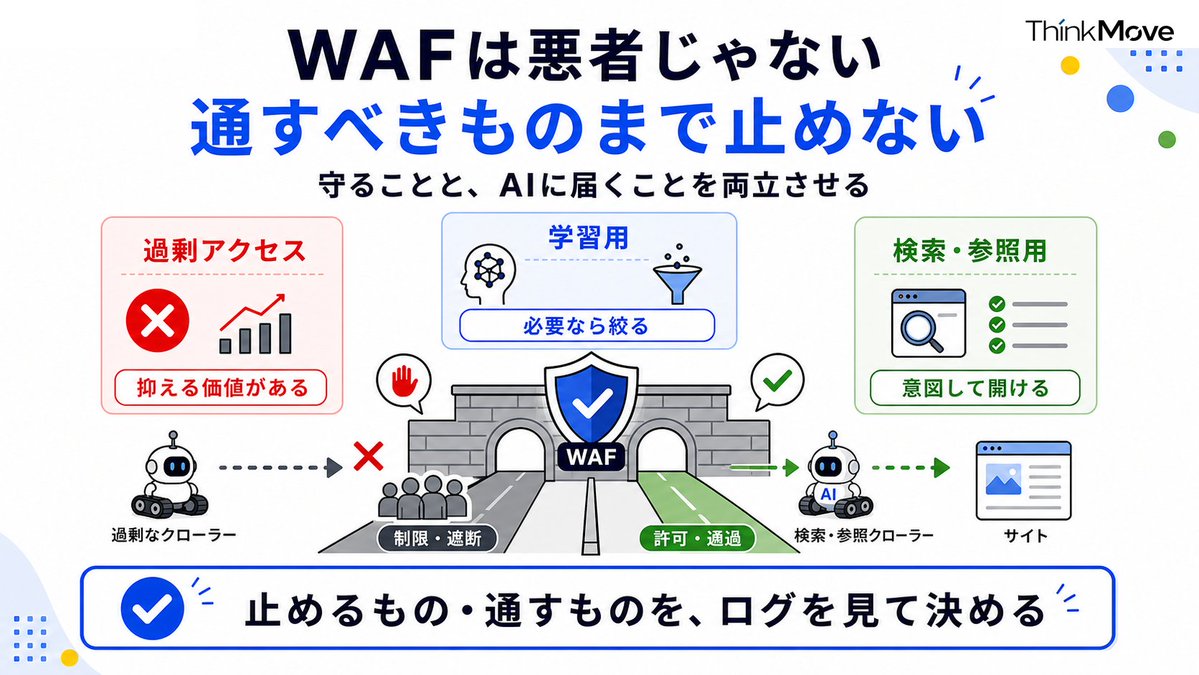
誤解してほしくないのですが、WAF(不正アクセスを防ぐ仕組み)を入れるな・AIを全部通せ、という話ではないです。
AIクローラーのアクセスは年々えげつなく増えていて、学習用のクローラーが大量に叩いてサーバーが重くなる、という相談も普通にある。過剰なアクセスを抑える意味でWAFは有効だし、入れたほうがいいケースも多い。
ただ怖いのは、止めたいものじゃなく、通したいものまで止めてしまうこと。
最近のAIクローラーは用途で種類が分かれてきていて、「AIの学習用」と「ユーザーがその場で質問したときに見に来る検索・参照用」は別物として整理されつつあります。
前者は負荷対策で絞ってもいいけど、後者まで一緒に弾くと「AIに引用・紹介してもらう経路」を自分で塞ぐことになります。

最近は人間のふりをして(普通のスマホのブラウザを装って)来るAIもいて、こうなるとセキュリティ側が「動きが怪しい」と判断して弾く、みたいなことも起きる。
たとえばCloudflareのようなサービスだと、AIをまとめてブロックする設定が最初から強めに入っていることがある。気づかないうちに自社で全部止めていた、というのはよくある話です。
WAFを使うなら、
- いきなり全部ブロックせず、まず「記録だけして遮断はしない」状態で様子を見る
- ログで「実際に何が来ているか」を確認する
- そのうえで、止めるもの・通すものを意図して決める
この順番が安全かなと。ここを雑にやると、あとで「なんでAIに出てこないんだろう」と悩むハメになります。
余談ですが、これを知らないと、急にDirectのトラフィックめちゃくちゃ増えて、成果出たように見えたりもします。
とりあえず、解析の難易度上がりすぎやで….
LLMOを語る前に、足元を確認する
結局、構造化データもllms.txtも、サイトがAIに認識されているのが大前提の話で。入口でフェッチ(取得)が弾かれていたら、その先をどれだけ綺麗に整えてもAIは読めない。
LLMO対策と言いながら、そもそも届いていない。笑い話みたいだけど、わりと真面目に起きています。
逆に言うと、入口さえちゃんと開いていれば、最近のAIはサイトの情報を結構素直に参考にしてくれる印象があります。だからこそ、足元を固める価値がある。
「うちもLLMOやらなきゃ」と思ったら、施策を増やす前に一回だけ確認してみてほしい。
- 自分のサイトを、ChatGPTやClaudeに「このページ読んで」と投げてみる
- ちゃんと中身を読めているか、「取得できませんでした」になるか
取れないなら、サーバーのアクセスログとセキュリティ設定を見る(社内のエンジニアや制作会社に聞くのが早いです)
それだけで「あれ、うち届いてないかも」が見つかるサイトは、結構あると思います。
派手な対策の前に、足元のドアが開いているか。まずはそこからかなと思います。
【おまけ】自分で手を動かせる人向け・実践チェック
ここから先はちょっと技術寄り。社内のエンジニアや制作会社に渡してもらえれば、その場で確認できます。
AIクローラーを名乗ってアクセスし、サーバーがどう応答するかを見るコマンドの例。
bash
# Claude
curl -I -A “Mozilla/5.0 (compatible; ClaudeBot/1.0; +https://anthropic.com)” https://example.com
# OpenAI(検索・参照用。ここが通っているかが特に大事)
curl -I -A “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; OAI-SearchBot/1.0; +https://openai.com)” https://example.com
# Perplexity
curl -I -A “Mozilla/5.0 (compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)” https://example.com
見るポイント。
200 OK が返れば基本OK。403(拒否)・429(アクセス過多扱い)・5xx(サーバーエラー)はアウト
Content-Length が異常に小さいときは、中身が空=プログラム描画待ちで本文が返っていない疑い
どれも、人間のブラウザでは普通に見えてしまうので、この確認をしないと気づけない
切り分けの順番。
- ブラウザ(ログインしていない状態)で普通に見えるか
- 上のコマンドで、AIクローラーに対する応答コードを確認
- /robots.txt が正常(200)で返るか、AIクローラーをどう扱っているか
- サーバーのアクセスログ/エラーログで、当該クローラー・当該URLの応答を実地確認
ログに記録が無ければ、WAF/CDN側のログを見る(手前の層で弾かれている可能性)
という感じです。どう切り分けるべきか、進め方から考えますので、お気軽にご相談ください!
- 【登壇のお知らせ】Faber Company主催「ハイブリッドオフィスアワー SEO/GEOのいま、現場のホンネ」に登壇します
- Notionをナメてた話|Claude Code × Notion CLIでAIに運用させたら全部変わった
この記事を書いた人
関連記事
-
 【イベントレポート】「LLMOって結局なに?」AI検索対策が分かりにくい理由を、支援者2人が読み解く
【イベントレポート】「LLMOって結局なに?」AI検索対策が分かりにくい理由を、支援者2人が読み解く -
BigQueryなしでGA4・GSCデータを蓄積する方法|SQLiteで擬似BigQueryを作る
-
Notionをナメてた話|Claude Code × Notion CLIでAIに運用させたら全部変わった
-
「最適化」という言葉が、SEOとLLMOに合わなくなってきた。
-
GA4の「Direct」急増はAI流入が原因?ChatGPTに引用されても計測できない仕組みと対策
-
見積書が判断を殺す。「レポートよりも、判断がほしい」時代
-
2026年のSEO戦略「やらないこと」を決める3つの撤退ライン
-
BtoBマーケの「当たらない予測」、そろそろやめませんか?







